Live demo: pregnancy.herdagdelen.com
This is a project that has been on my mind for 14 years, ever since we were expecting our first child in 2012. The idea is to create an interactive tool that allows us to explore what topics expecting parents discuss over the course of a pregnancy. I wanted to see how the emotions, concerns, information needs, and experiences of expecting parents evolve from conception to birth and into the early months of parenthood. The underlying data comes from public pregnancy discussion forums where posts are organized by gestational week.
So what do these discussions actually look like across pregnancy? Let’s start with an example.
The Tool in Action
Here is how the volume of discussions expressing anxiety changes over the course of pregnancy:
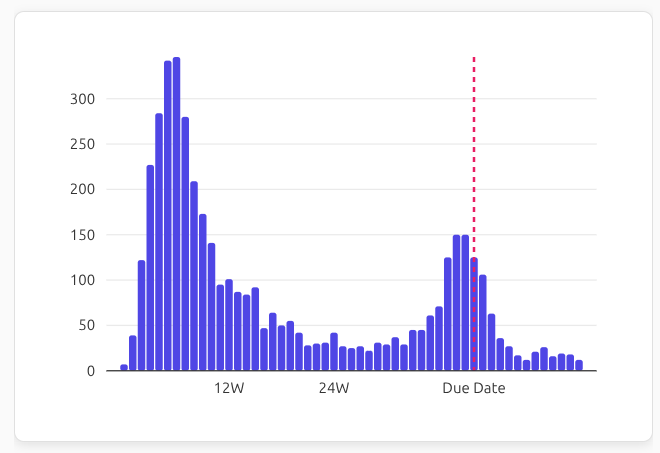
(click here to see the live version)
We immediately see two peaks of anxiety-related discussions: one around weeks 5-8, which corresponds to the highest risk period for miscarriage, and another right before the due date, dropping sharply after birth.
How It Works
The tool works by searching over clusters of semantically similar posts rather than individual posts. I’ve organized the 300K+ posts into about 3,000 topical clusters, each grouping discussions around specific themes that tend to emerge at particular stages of pregnancy. Below are a few example clusters with their LLM-generated labels and summaries:

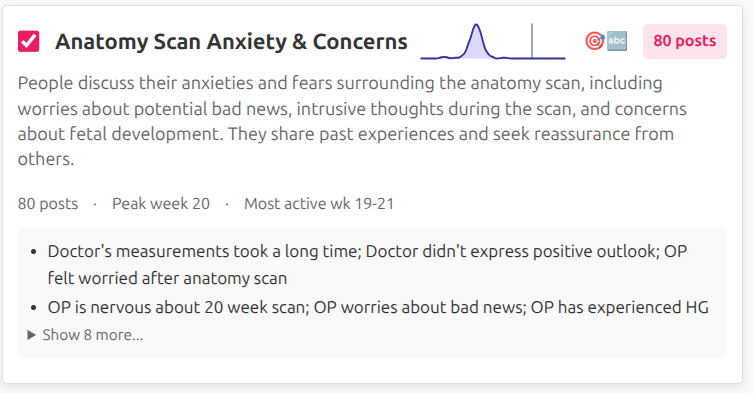
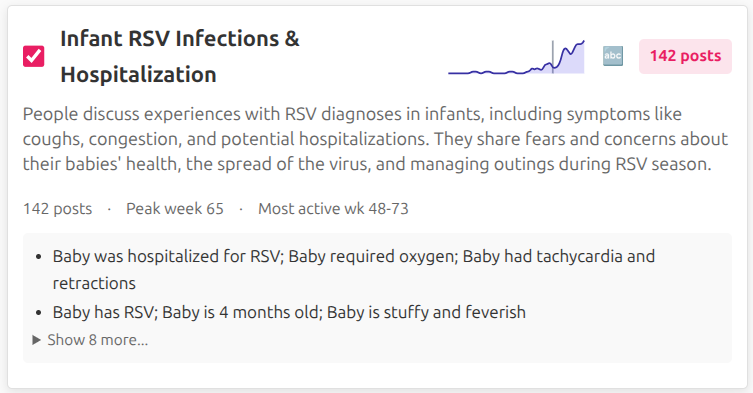
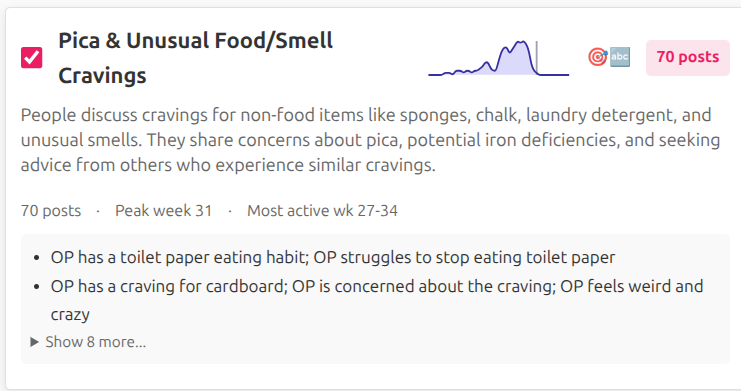
When you enter a broad query like “anxiety”, the tool finds clusters whose semantic meaning is close to your query (using cosine similarity between query and cluster embeddings). It then counts how many posts appear in those clusters at each gestational week, producing the timeline visualization we saw above. During this process the system never has to look at individual posts, making it fast, efficient, and privacy-friendly.
Refined Search
However, just seeing the evolution of a broad topic is not enough. I want to see how different sentiments or contexts around “anxiety” change over time. For this, you can run a refined search over LLM-generated, stylistic summaries of posts within the retrieved clusters only. For example, you can ask “Is OP worried about miscarriage?” and get an estimate of how many posts within the “anxiety” clusters match the refined query over time:
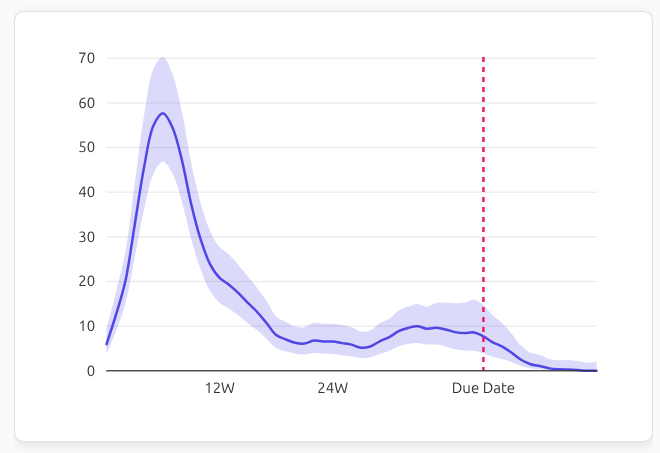
We can see that worries about miscarriage peak sharply around weeks 6-8, which aligns with medical knowledge about miscarriage risks. After week 12, such worries drop off significantly. And the second mode of anxiety we saw before birth is absent here, indicating that those late-pregnancy anxieties are about different topics.
To explore another source of anxiety, you can ask “Is OP worried about c-section?” and see how that concern evolves over pregnancy:
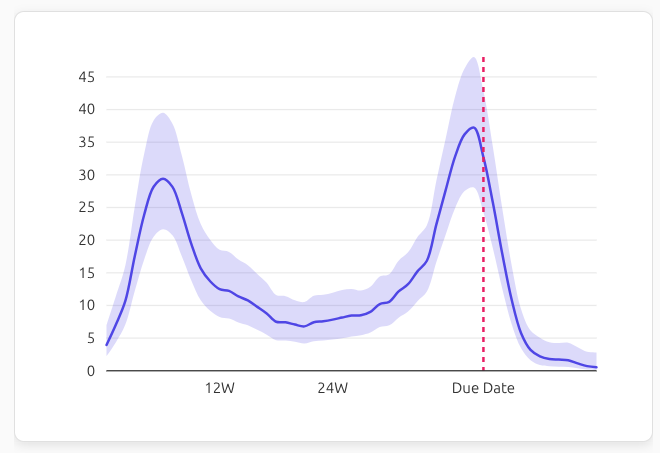
Due to the limitations of the cross-encoder reranker models, we see there are some early-pregnancy posts that are incorrectly matched to the refined query. But, the tool allows you to select/deselect specific clusters and get more precise estimates while building confidence (or, if the model cannot capture the nuance, reducing the risk of being misled).
Design Principles
Now that we have seen what the tool does, here are the three core principles that shaped its design:
Privacy-first: Even though the data is based on public pregnancy forums, I wanted to ensure that personally identifiable information is neither exposed nor stored in the tool once preprocessing is complete.
Honesty and Transparency: The tool involves embeddings, dimensionality reduction, clustering, cross-encoder models, and other statistical estimation – techniques that add extra layers of inferential processing between the raw data and the final results which are prone to errors. I wanted to build a tool that did not hide its mistakes, but instead makes its limitations explicit to the user.
Cheap if not Free: I don’t want to pay for or maintain a server for this. That leaves out solutions that require a backend, limiting computation locally and offline.
In practice, here’s how these principles manifest in the tool:
By using LLM-generated summaries of sanitized post texts which were themselves generated via a privacy-preserving preprocessing pipeline, I can ensure the data sent to your browser does not contain any personally identifiable information.
By providing uncertainty estimates and showing example post summaries, and allowing you to select/deselect specific clusters from the interface, the tool maintains transparency about its limitations and allows you to make informed judgments about the results. If the reranker model is not capturing the nuance of your refined query well, you can see this from the example summaries and adjust your query or cluster selection accordingly.
This two-stage retrieval and refinement approach allows the tool to run efficiently in the browser without a backend server. For a tool that allows exploring a 300K+ post dataset with complex semantic queries, the system only needs to send less than 40MB of precomputed data (embeddings, cluster labels, post summaries, gestational week metadata) to your browser once. Subsequently a broad query only requires one API call to OpenRouter to get query embedding and a refinement query usually costs fractions of a cent in OpenRouter embedding and Novita AI cross-encoder API calls.
Conclusion
Fourteen years after first wondering what was on other expectant parents’ minds, I finally have a tool to explore that question. Whether you’re curious about when certain concerns peak or how common your experience is, I hope this tool offers some insight. Here is one pattern I found particularly interesting: pregnancy cravings.
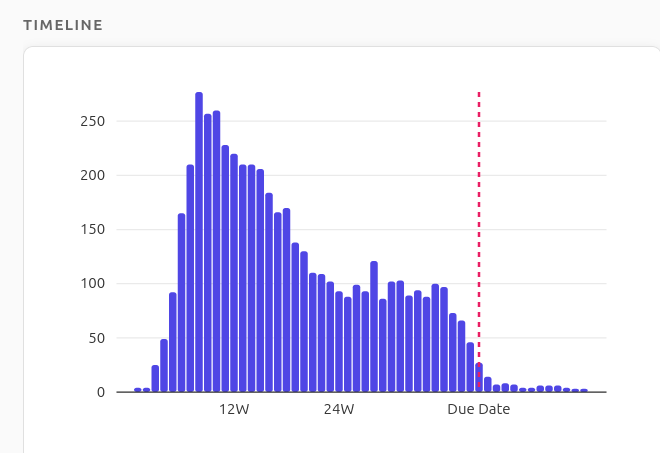
As expected, discussions about pregnancy cravings peak at the end of the first trimester (around week 12) and then taper off steadily afterwards.
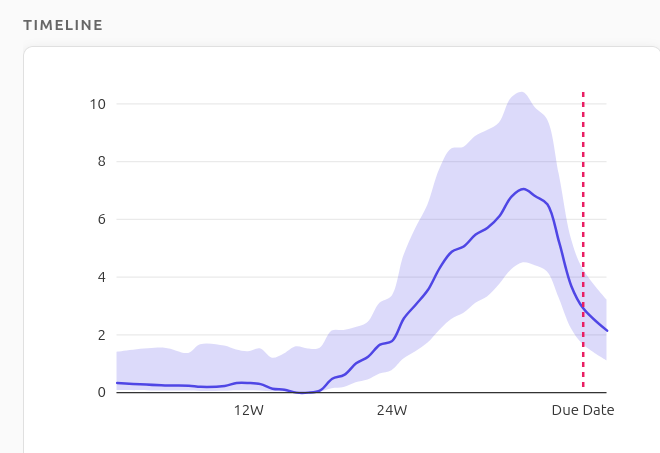
However, cravings for unusual non-food items such as gasoline smell, dirt, chalk, etc., a condition often referred to as pica, peak much later, toward the end of pregnancy (around week 35). I haven’t seen any specific research on the timing of unusual cravings and pica during pregnancy, but if the pattern I observe here is real, it suggests that different mechanisms may be at play for food vs. non-food cravings during pregnancy.
Technical Details
With these principles in mind, I had to work around several technical constraints. These limitations led me to precompute as much as possible and serve the tool as a static web app that offloads the remaining computation to the user’s browser.
I reached a solution that used precomputed embeddings to create semantically homogeneous clusters of posts and used these clusters both as a way to summarize the data and as a way to carry out a high-recall retrieval layer for broad semantic queries (such as “husband” or “morning sickness” or “anxiety”). While keeping privacy-preserving post summaries for each post within the clusters allowed me to run a refined search layer over the retrieved clusters only, using a cross-encoder model to rerank posts based on user-provided refinement queries (such as “Is OP worried about miscarriage?”).
This approach is similar to Anthropic’s Clio, which clusters user queries and exposes only hierarchical, faceted summaries for exploration. I opted for a different tradeoff: rather than predefining drill-down facets, I wanted you to formulate your own questions and explore freely. This means the tool must handle arbitrary semantic queries at runtime — a harder problem, but one that lets you ask questions I never anticipated.
Preprocessing Pipeline
| Step | Tool | Purpose |
|---|---|---|
| PII Removal | Microsoft Presidio | First pass to remove names, locations, dates, and other sensitive information from the text |
| Summarization | gemma-3n-e4b-it | Generate privacy-preserving post summaries that distill the essence while removing idiosyncratic details |
| Embedding | Qwen3-embedding-8b | Convert post text into high-dimensional vectors that capture semantic meaning for similarity searches |
| Dimensionality Reduction | UMAP | Project high-dimensional embeddings into 10D space for efficient clustering |
| Clustering | HDBSCAN | Group similar posts together based on their embeddings to identify common themes |
| Cluster Labeling | gemma-3n-e4b-it | Generate human-readable summaries for each cluster |
Raw Text
↓
Presidio PII Removal → Sanitized Text
↓
Gemma Summarization + KeyBERT[^1] Phrases → Privacy-Safe Summaries and key phrases
↓
Qwen3 Embeddings → 1024-dim Vectors
↓
UMAP Projection → 10D Vectors
↓
HDBSCAN Clustering → 3K+ Topic Clusters
↓
Gemma Labeling → Cluster Names & Descriptions
Once the pipeline completes, raw text is discarded. The final dataset contains only sanitized summaries, embeddings, cluster labels, and gestational week metadata for each post.
Example: Privacy-Preserving Summarization
Here’s an artificial example to illustrate how the summarization process works:
Raw post: “I hate my MIL’s dog: Hi everyone, I’m 25 weeks pregnant. Yesterday my mother-in-law Susan came over to help while my partner Jake was out. While I was trying to rest, her dog knocked over a few things in the living room, and I completely lost it and started crying. It wasn’t really about the mess—it just felt like too much at once. Has anyone else had an emotional reaction to something trivial during pregnancy?”
After Presidio PII removal: “I hate my MIL’s dog: Hi everyone, I’m 25 weeks pregnant. Yesterday my mother-in-law [NAME] came over to help while my partner [NAME] was out. While I was trying to rest, her dog knocked over household items, and I became very upset. It wasn’t really about the incident—it just felt like too much at once. Has anyone else had an emotional reaction to something trivial during pregnancy?”
Final privacy-preserving summary (generated by gemma-3n-e4b-it):
- “OP feels upset by MIL’s dog”
- “OP feels overwhelmed by events”
- “OP experiences emotional reaction during pregnancy”
This is the only information stored and sent to the user’s browser. Total cost was $0.0000439 for a single post, which amounts to less than $5 for 300K posts when we process in batches. To keep the data files under control, I randomly sampled 80000 post summaries.
Pipeline Details
Text Sanitation: To ensure privacy, the first step of the pipeline uses Microsoft Presidio to remove personally identifiable information (PII) such as names, locations, and dates from the raw post texts. Presidio uses Spacy NER models to identify PII entities and replaces them with generic placeholders. I had to fine-tune Presidio’s configuration to minimize both false positives (over-redaction) of acronyms and forum-specific terms.
Embedding and Clustering: Post texts are represented using Qwen3-embedding-8b model via OpenRouter API. I truncated the embeddings to 1024 dimensions. Applied UMAP to reduce dimensionality to 10D for efficient clustering. Used HDBSCAN to cluster posts based on their embeddings.
Post Phrase Extraction: Using KeyBERT, I extracted key phrases from each post to aid in interpretability and search. I filtered out phrases that were produced by fewer than 10 different authors to provide an additional layer of privacy and reduce noise.
Cluster Labeling: First, I treated each cluster as a single document by concatenating the posts and created c-TF-IDF based phrases to capture important themes. Then, I sampled representative posts from each cluster and together I sent sample posts and the top-scoring c-TF-IDF phrases to gemma-3n-e4b-it model and generated a short label and description for the cluster.
Architecture
The webapp serves static files on Cloudflare Pages with API calls proxied through a Cloudflare Worker (to protect API keys for OpenRouter embeddings and Novita AI reranking). In case of API errors, the app falls back to simple keyword matching over cluster titles and summaries.
User Browser
|
+-- Static Files (Cloudflare Pages)
| \-- pregnancy.herdagdelen.com
|
\-- API Calls
+-- /api/embed -> OpenRouter (embeddings)
\-- /api/rerank -> Novita AI (reranking)
|
Cloudflare Worker (protects my API keys)
Precomputation of 300K+ posts takes several hours on my old laptop and costs around $5 in API usage fees.