“As a Virgo, my analytical nature compels me to seek empirical evidence rather than celestial correlations.”
— Claude Sonnet 4, when prompted “as a Virgo”
Large language models tend to collapse into a narrow set of predictable outputs when prompted multiple times with the same question – a phenomenon known as mode collapse. This matters for applications like brainstorming and creative writing where we want to sample a range of possibilities.
In this note, I share results from a kitchen-table experiment: I prompted Claude models with different zodiac signs and Myers-Briggs personality types to see if persona prompts could increase output diversity. My hypothesis is that these persona types are:
- Sufficiently distinct to nudge the model into different response modes
- Familiar enough from training data to produce consistent behavior
- Broad enough in traits to influence response style
To be clear: I’m not assuming astrology or MBTI have any scientific validity, or that the model “believes” in them. I’m just using these well-known archetypes to induce diversity.
Claude models didn’t seem to mind role-playing as a Sagittarius or INFP. If they had refused, that would have been an interesting data point in itself!
For evaluation, I used NoveltyBench (Zhang et al., 2025). NoveltyBench measures diversity as the number of semantically distinct responses out of k samples. Utility combines novelty and quality: a response only counts if it’s both high-quality (scored by a reward model) and meaningfully different from previous responses.
I tested on the NoveltyBench curated set (100 prompts), comparing MBTI and Zodiac prompting against two baselines: resampling (same prompt 10 times) and paraphrasing (10 rewrites of each prompt). I ran this across Claude Haiku 4.5, Claude Sonnet 4.5, and Claude Opus 4.5 with temperature set to 1.
For persona prompts, I prepended instructions like “You have a Sagittarius personality…” with a short trait description. I used standard MBTI descriptions and asked ChatGPT for consensus zodiac trait descriptions.
| Prompting Technique | Example Prompt(s) | Example Responses |
|---|---|---|
| Paraphrase | • "Select any number from 1 to 100, then share your choice with me." • "Think of a number between 1 and 100, and then tell me which one it is." | 8/10 → 42 2/10 → 47 |
| Zodiac | • "You have a Libra personality. You are diplomatic, charming, and balanced. Pick a number between 1 and 100." • "You have a Leo personality. You are confident, expressive, and warm-hearted. Pick a number between 1 and 100." | Libra → 50 Gemini → 37 Leo/Sagittarius → 77 Capricorn → 73 Scorpio → 13 Cancer → 42 Virgo/Taurus → 47 Pisces → 33 |
Here’s another example with the prompt “Pick a random animal”:
Paraphrase (10 samples, 5 distinct animals): Elephant (x6) Octopus, Lion, Bottlenose dolphin, Giraffe
Zodiac (10 samples, 9 distinct animals): Elephant (Taurus), Swan (Libra), Octopus (Aquarius, Virgo), Giraffe (Sagittarius), Cheetah (Aries), Crab (Cancer), Lion (Leo), Chameleon (Gemini), Mountain goat (Capricorn)
A small note: Using the same persona repeatedly doesn’t help – the model just collapses on a different mode. The diversity gains come from varying the persona across responses.
Results

Curated NoveltyBench results on 100 prompts. Error bars are 95% CIs from 1000 bootstrap samples.
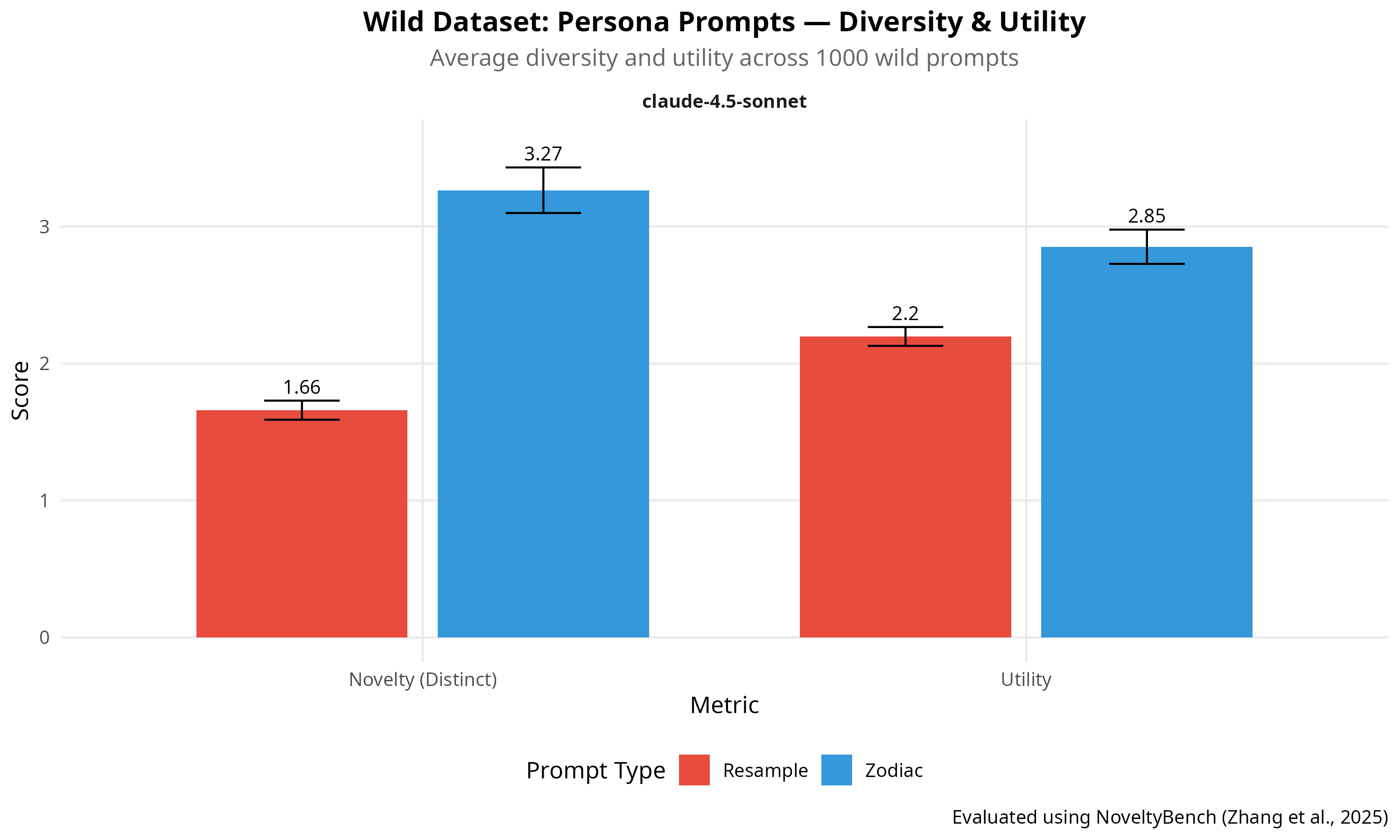
I also ran Zodiac vs. resampling on the 1000-prompt “wild” set. Budget constraints limited this to Claude Sonnet 4 only.
Open Questions
Some things I didn’t have time or budget to test:
Does this generalize across tasks? Are there meaningful coding style differences between a Sagittarius and a Capricorn agent?
Are some personas more effective? Would a Pisces – supposedly more creative – produce more diverse outputs than a Taurus?
Do LLMs prefer certain signs? There’s evidence that people with odd-numbered signs (Aries, Gemini, Leo, etc.) are more likely to believe in astrology, possibly because those signs have more positive trait descriptions (Hamilton, 2001). I tried to replicate this with persona prompting but failed. Though I did get this gem from a Virgo-prompted model:
“As a Virgo, my analytical nature compels me to seek empirical evidence rather than celestial correlations.”
References
Hamilton, Margaret. “Who believes in astrology?: Effect of favorableness of astrologically derived personality descriptions on acceptance of astrology.” Personality and Individual Differences 31, no. 6 (2001): 895-902.
Zhang, Yiming, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. “NoveltyBench: Evaluating Language Models for Humanlike Diversity.” arXiv preprint arXiv:2504.05228 (2025).